This research looks at a very big question for society right now, can AI systems be ethical? This is more than just whether they can be “aligned” with human values, whatever that means, but whether they can actually perform ethical reasoning and make ethical decisions. This is a very difficult question to answer, but we are making some progress on it in the lab. We are looking at ways to formalize ethical reasoning and decision making with respect to Reinforcement Learning, which has it’s own inherent ethical bias when the full range of ethical behaviours is considered.
Our Papers on Machine Ethics
Can Standard MARL Metrics Distinguish Communicative from Strategic Action?
In
ICML 2026 Workshop: Philosophy Meets Machine Learning.
2026.
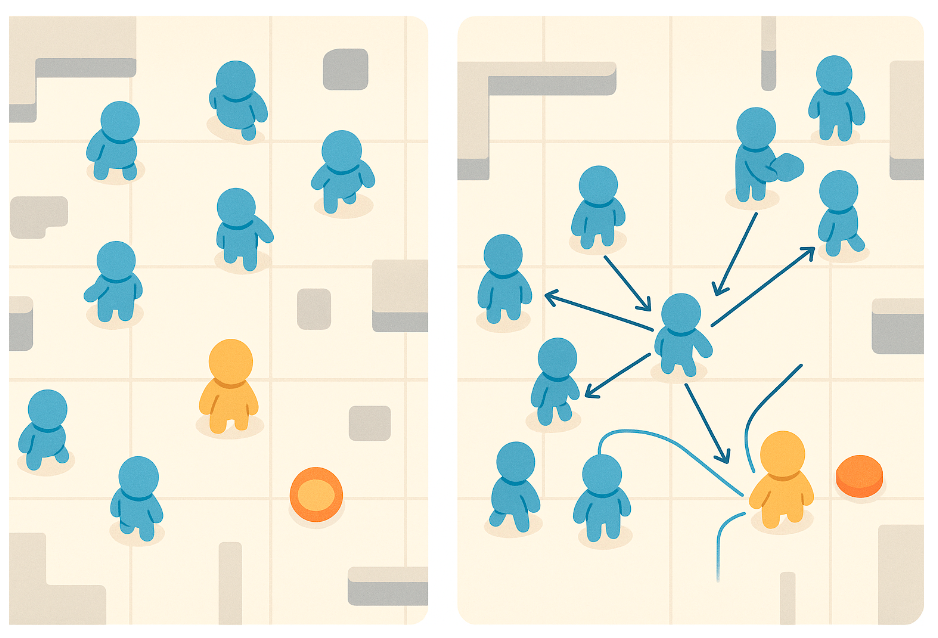
Multi-agent Reinforcement Learning (MARL) systems are routinely evaluated using aggregate utility metrics. A population that converges to high reward is often described as having reached "consensus". Drawing on @habermas1984, we distinguish a justified consensus from strategic action. Standard MARL objectives collapse the distinction: both record as similarly successful. We demonstrate the gap in a minimal foraging environment with one "Tyrant" agent that can unilaterally penalize peers. The system converges to high-reward equilibria nearly indistinguishable from a symmetric baseline by standard metrics. A coercion index, tracking how peers yield to credible threats, exposes what aggregate return hides. Trustworthy MARL evaluation requires diagnostics explicitly sensitive to capability asymmetry.
Rethinking AI Alignment: From Static Rewards to Social Reinforcement Learning
In
Pluralistic Alignment Workshop at ICML 2026.
2026.
Despite the widespread adoption of Reinforcement Learning from Human Feedback, state-ofthe-art AI systems remain prone to two persistent failure modes: hallucination (producing fluent but false content) and moral drift (the convergence towards exploitative or harmful equilibria). We argue that these are not distinct phenomena but
plausibly arise from a single underlying cause: feedback collapse. This occurs when complex human values are compressed into fixed scores and frozen offline, decoupling the training signal from the true goals of truth and rightness. We argue that optimizing for these proxies tends to misalign the learning process under distribution
shift. To address this, we propose Social Reinforcement Learning (Social RL) as a promising route to structurally enforcing feedback integrity. By situating agents in social environments driven by peer critique, reputation, observation, and sanction, Social RL treats alignment as an ongoing negotiation rather than a static specification problem, and offers mechanisms for correcting epistemic errors and stabilizing ethical norms in open-ended
environments.
Toward Virtuous Reinforcement Learning: A Critique and Roadmap
In
Workshop on Machine Ethics: From Formal Methods To Emergent Machine Ethics at AAAI 2026..
Singapore.
Jan,
2026.
This paper critiques common patterns in machine ethics for Reinforcement Learning (RL) and argues for a virtue focused alternative. We highlight two recurring limitations in much of the current literature: (i) rule based (deontological) methods that encode duties as constraints or shields often struggle under ambiguity and nonstationarity and do not cultivate lasting habits, and (ii) many reward based approaches, especially single objective RL, implicitly compress diverse moral considerations into a single scalar signal, which can obscure trade offs and invite proxy gaming in practice. We instead treat ethics as policy level dispositions, that is, relatively stable habits that hold up when incentives, partners, or contexts change. This shifts evaluation beyond rule checks or scalar returns toward trait summaries, durability under interventions, and explicit reporting of moral trade offs. Our roadmap combines four components: (1) social learning in multi agent RL to acquire virtue like patterns from imperfect but normatively informed exemplars; (2) multi objective and constrained formulations that preserve value conflicts and incorporate risk aware criteria to guard against harm; (3) affinity based regularization toward updateable virtue priors that support trait like stability under distribution shift while allowing norms to evolve; and (4) operationalizing diverse ethical traditions as practical control signals, making explicit the value and cultural assumptions that shape ethical RL benchmarks.