See newsitem : lab news 2026-05-07
Our Papers on Vision Language Navigation
View Invariant Learning for Vision-Language Navigation in Continuous Environments
Josh Qixuan Sun,
Huaiyuan Weng,
Xiaoying Xing,
Chul Min Yeum,
and
Mark Crowley
IEEE Robotics and Automation Letters.
11,
(5).
2026.
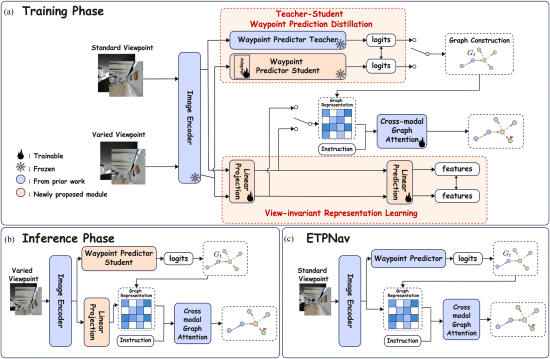
Vision-Language Navigation in Continuous Environments (VLNCE), where an agent follows instructions and moves freely to reach a destination, is a key research problem in embodied AI. However, most existing approaches are sensitive to viewpoint changes, i.e. variations in camera height and viewing angle. Here we introduce a more general scenario, V2-VLNCE (VLNCE with Varied Viewpoints) and propose a view-invariant post-training framework, called VIL (View Invariant Learning), that makes existing navigation policies more robust to changes in camera viewpoint. VIL employs a contrastive learning framework to learn sparse and view-invariant features. We also introduce a teacher-student framework for the Waypoint Predictor Module, a standard part of VLNCE baselines, where a view-dependent teacher model distills knowledge into a view-invariant student model. We employ an end-to-end training paradigm to jointly optimize these components. Empirical results show that our method outperforms state-of-the-art approaches on V2-VLNCE by 8-15% measured on Success Rate for two standard benchmark datasets R2R-CE and RxR-CE. Evaluation of VIL in standard VLNCE
settings shows that despite being trained for varied viewpoints, VIL often still improves performance. On the harder RxR-CE dataset, our method also achieved state-of-the-art performance across all metrics. This suggests that adding VIL does not diminish the standard viewpoint performance and can serve as a plug-and-play posttraining method. We further evaluate VIL for simulated camera placements derived from real robot configurations (e.g. Stretch RE1, LoCoBot), showing consistent improvements of performance. Finally, we present a proof-of-concept real-robot evaluation in two
physical environments using a panoramic RGB sensor combined with LiDAR. These results show that VIL improves robustness not only in simulation but also in real-world navigation scenarios, making it a practical strategy for embodied agents. The code is available at https://github.com/realjoshqsun/V2-VLNCE.