Automated Materials Design and Discovery Using Reinforcement Learning
Studying how to automate material synthesis and discovery by training a Deep Reinforcement Learning system to plan and carry out chemical synthesis experiments to gather data and find efficient pathways to making new or known materials.
DOMAINS | ai-for-science
WEBPAGE: http://chemgymrl.com
This project is the result of a collaboration sponsored by the National Research Council – UW Collaboration Centre (NUCC) on AI/Cybersecurity/IoT. This organization was set-up around 2019 to initiate research collaboration between NRC staff researchers and UWaterloo PIs. I was one of the first faculty members to be a part of this endeavour and to receive funding for my work. With Dr. Isaac Tamblyn (NRC) and Dr. Colin Bellinger (NRC), our project studies how to automate material synthesis and discovery by training a Deep Reinforcement Learning system to plan and carry out chemical synthesis experiments to gather data and find efficient pathways to making new or known materials.”
To see the latest state of this project take a look at the papers below. If you are interested in using our framework you can check the detailed documentation site which includes tutorials, example code and explanations. You can or even contributing to it, you can do that through the wefind out more, take a look at the current framework to carry out your own experiments or contribute to the framework: chemgymrl.com
Problem Description
The main idea is described most recently in our ICML workshop paper (Beeler et al., 2023) with some great high-level summary and motivation. These papers (Bellinger et al., 2022), (Bellinger et al., 2023) also show results of modification to the standard single-action RL framework, to divide actions into two parts containing a costly observation choice in addition to the usual action which affects the world.
Motivation
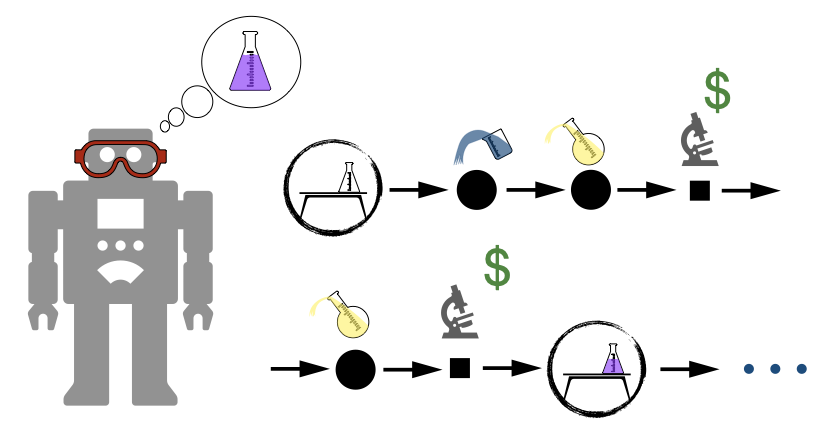
The goal of ChemGymRL is to simulate enough complexity of real-world chemistry experiments to allow meaningful exploration of algorithms for learning policies to control bench-specific agents, while keeping it simple enough that episodes can be rapidly generated during the RL algorithm development process. The environment supports the training of RL agents by associating positive and negative rewards based on the procedure and outcomes of actions taken by the agents. The aim is for ChemGymRL to help bridge the gap between autonomous laboratories and digital chemistry. This will have impacts for producing new materials, chemicals, and drugs. It will also require many technologies including search, feedback and control, and optimization, and artificial intelligence algorithms that can deal with the unique challenges of material design. This simulation environment encapsulates some of those challenges while maintaining as much realism as possible, and extensibility to allow open-source improvement of the simulations going forward. The framework raises interesting computational and modeling challenges for the Reinforcement Learning paradigm that are not always all present in other frameworks such as costs of observation, observations of various level of detail and hierarchical planning.
The Library
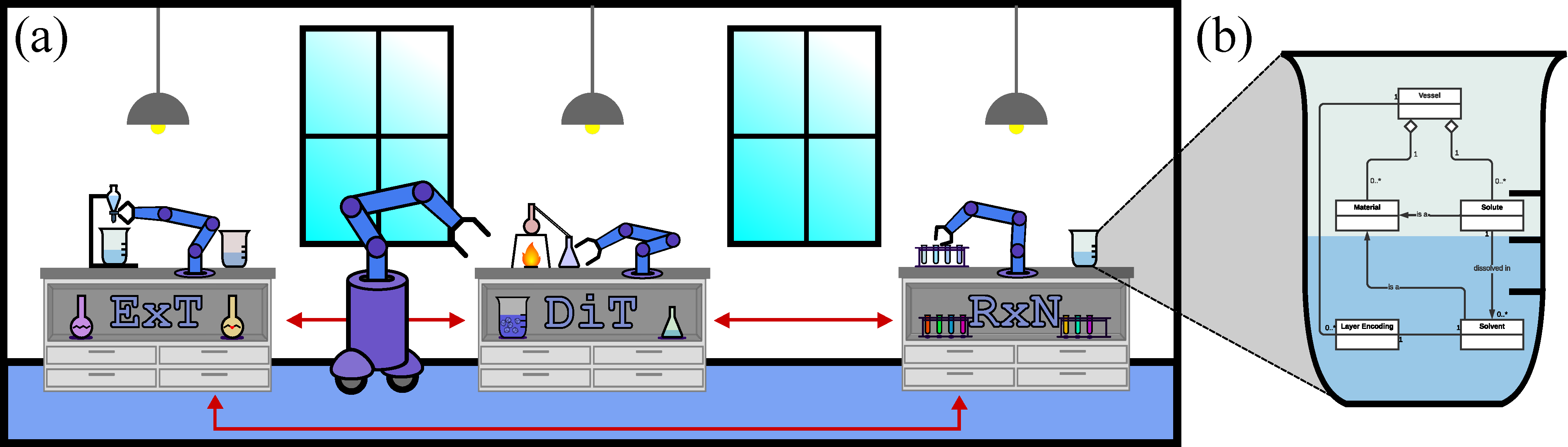
The ChemGymRL Open Source Library enables the use of Reinforcement Learning (RL) algorithms to train agents towards the target of operating individual chemistry benches given specific material targets. The environment can be thought of as a virtual chemistry laboratory consisting of different stations (or benches) where a variety of tasks can be completed. The laboratory consists of three basic elements: vessels, shelves, and benches. Vessels contain materials, in pure or mixed form, with each vessel tracking the hidden internal state of their contents. Whether an agent can determine this state, through measurement or reasoning, is up to the design of each bench and the user’s goals. A shelf can hold any vessels not currently in use, as well as the resultants (or output vessels) of previous experiments. Benches are sub-environments which enact various physical or chemical processes on the vessels. Each bench recreates a simplified version of one task in a material design pipeline and has an observation and action space specific to the task at hand.
ChemGymRL is designed in a modular fashion so that new benches can be added or modified with minimal difficulty or changes to the source code. A bench must be able to receive a set of initial experimental supplies, possibly including vessels, and return the results of the intended experiment, also including modified vessels. The details and methods of how the benches interact with the vessels between these two points are completely up to the user, including the goal of the bench. In this initial version of ChemGymRL we have implemented some core benches, which we describe in the following sections and which will allow us to demonstrate an example workflow.
Our Papers on ChemGymRL
- Reinforcement Learning in a Physics-Inspired Semi-Markov EnvironmentIn Canadian Conference on Artificial Intelligence. Springer, Ottawa, Canada (virtual). May, 2020.