What could be more important that using AI to learn how to do science more effectively, to learn what doing science really means, to update good methods for modelling our universe and make great?
In my lab we have done work on a few focussed topics in this area:
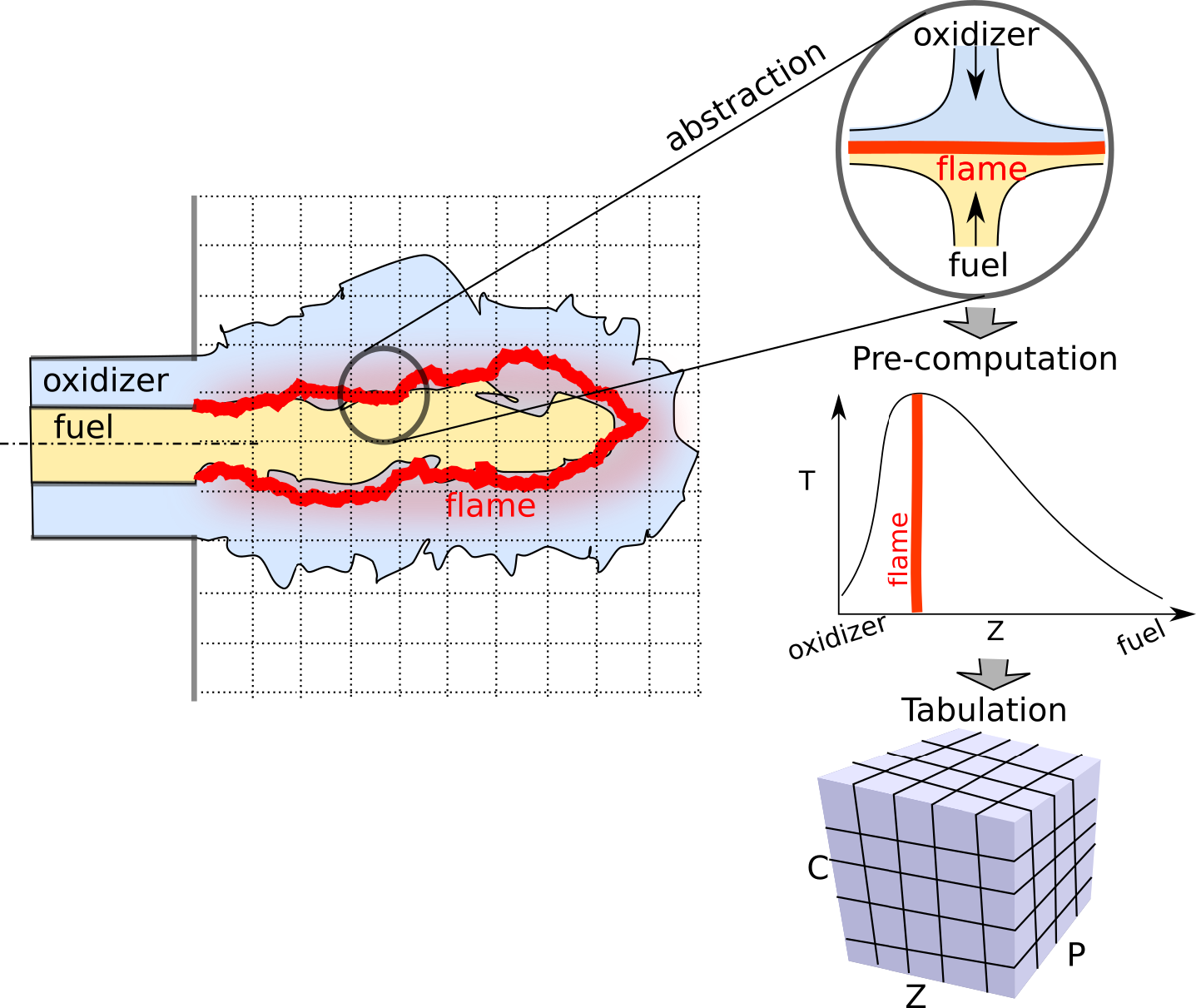
Combustion Modelling with Deep Learning
In the Combustion Modelling Project we used Deep Learning to greatly improve the speed and scale possible for existing flamelet estimation models.
Material Design using RL
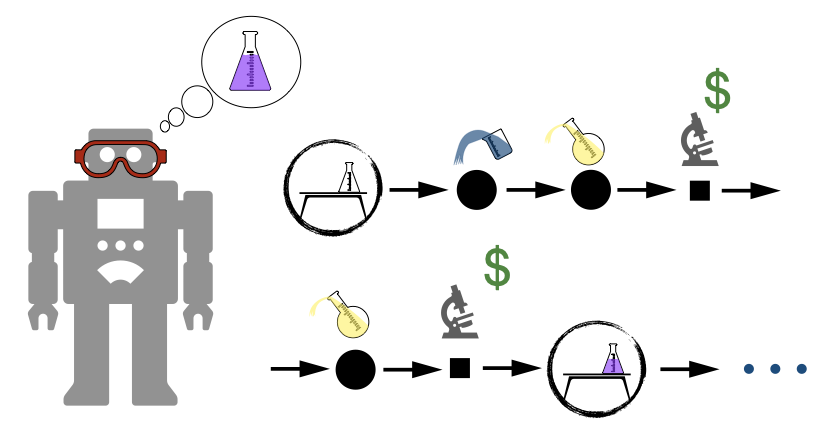
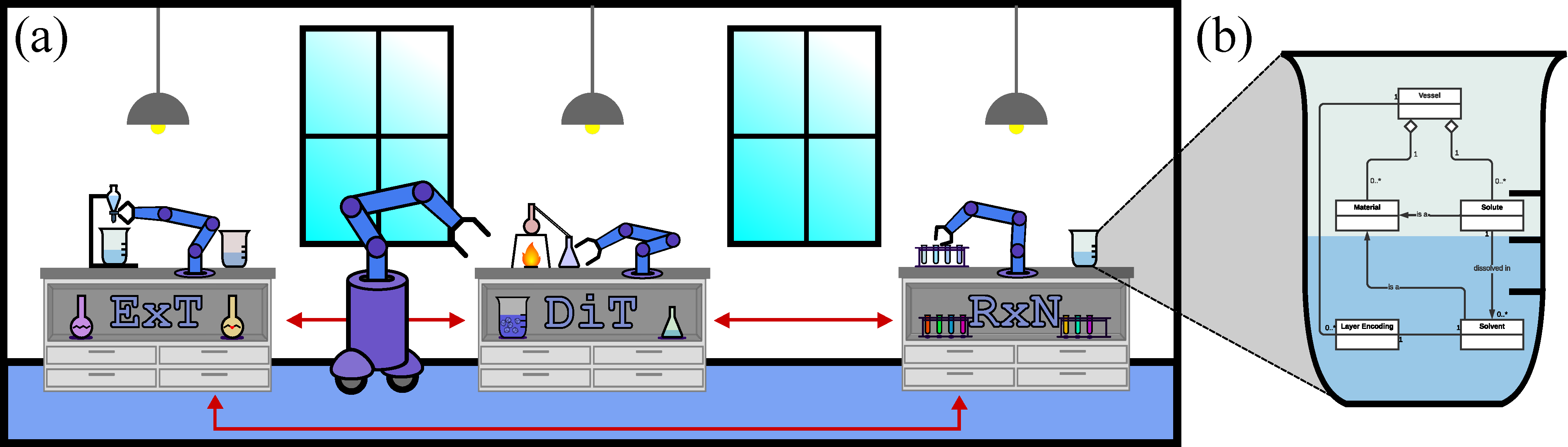
The Material Design Project is ongoing work with the National Research Council, where we are investigating exciting ways to apply Reinforcement Learning to the problem of material design and digital chemistry with our new open simulation framework : ChemGymRL.com.
Our Papers on AI for Science
ChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
Chris Beeler,
Sriram Ganapathi Subramanian,
Kyle Sprague,
Nouha Chatti,
Colin Bellinger,
Mitchell Shahen,
Nicholas Paquin,
Mark Baula,
Amanuel Dawit,
Zihan Yang,
Xinkai Li,
Mark Crowley,
and Isaac Tamblyn.
Digital Discovery.
3,
Feb,
2024.
This paper provides a simulated laboratory for making use of reinforcement learning (RL) for material design, synthesis, and discovery. Since RL is fairly data intensive, training agents ‘on-the-fly’ by taking actions in the real world is infeasible and possibly dangerous. Moreover, chemical processing and discovery involves challenges which are not commonly found in RL benchmarks and therefore offer a rich space to work in. We introduce a set of highly customizable and open-source RL environments, ChemGymRL, implementing the standard gymnasium API. ChemGymRL supports a series of interconnected virtual chemical benches where RL agents can operate and train. The paper introduces and details each of these benches using well-known chemical reactions as illustrative examples, and trains a set of standard RL algorithms in each of these benches. Finally, discussion and comparison of the performances of several standard RL methods are provided in addition to a list of directions for future work as a vision for the further development and usage of ChemGymRL.
Dynamic Observation Policies in Observation Cost-Sensitive Reinforcement Learning
In
Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (WANT@NeurIPS 2023).
New Orleans, USA.
2023.
Reinforcement learning (RL) has been shown to learn sophisticated control policies for complex tasks including games, robotics, heating and cooling systems and text generation. The action-perception cycle in RL, however, generally assumes that a measurement of the state of the environment is available at each time step without a cost. In applications such as materials design, deep-sea and planetary robot exploration and medicine, however, there can be a high cost associated with measuring, or even approximating, the state of the environment. In this paper, we survey the recently growing literature that adopts the perspective that an RL agent might not need, or even want, a costly measurement at each time step. Within this context, we propose the Deep Dynamic Multi-Step Observationless Agent (DMSOA), contrast it with the literature and empirically evaluate it on OpenAI gym and Atari Pong environments. Our results, show that DMSOA learns a better policy with fewer decision steps and measurements than the considered alternative from the literature.
ChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
In
NeurIPS 2023 AI for Science Workshop.
New Orleans, USA.
Dec,
2023.
This paper provides a simulated laboratory for making use of Reinforcement Learning (RL) for chemical discovery. Since RL is fairly data intensive, training agents ‘on-the-fly’ by taking actions in the real world is infeasible and possibly dangerous. Moreover, chemical processing and discovery involves challenges which are not commonly found in RL benchmarks and therefore offer a rich space to work in. We introduce a set of highly customizable and open-source RL environments, ChemGymRL, implementing the standard Gymnasium API. ChemGymRL supports a series of interconnected virtual chemical benches where RL agents can operate and train. The paper introduces and details each of these benches using well-known chemical reactions as illustrative examples, and trains a set of standard RL algorithms in each of these benches. Finally, discussion and comparison of the performances of several standard RL methods are provided in addition to a list of directions for future work as a vision for the further development and usage of ChemGymRL.
Demonstrating ChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
In
NeurIPS 2023 AI for Accelerated Materials Discovery (AI4Mat) Workshop.
New Orleans, USA.
Dec,
2023.
This tutorial describes a simulated laboratory for making use of reinforcement learning (RL) for chemical discovery. A key advantage of the simulated environment is that it enables RL agents to be trained safely and efficiently. In addition, it offer an excellent test-bed for RL in general, with challenges which are uncommon in existing RL benchmarks. The simulated laboratory, denoted ChemGymRL, is open-source, implemented according to the standard Gymnasium API, and is highly customizable. It supports a series of interconnected virtual chemical benches where RL agents can operate and train. Within this tutorial introduce the environment, demonstrate how to train off-the-shelf RL algorithms on the benches, and how to modify the benches by adding additional reactions and other capabilities. In addition, we discuss future directions for ChemGymRL benches and RL for laboratory automation and the discovery of novel synthesis pathways. The software, documentation and tutorials are available here: https://www.chemgymrl.com
ChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
Chris Beeler,
Sriram Ganapathi Subramanian,
Kyle Sprague,
Nouha Chatti,
Colin Bellinger,
Mitchell Shahen,
Nicholas Paquin,
Mark Baula,
Amanuel Dawit,
Zihan Yang,
Xinkai Li,
Mark Crowley,
and Isaac Tamblyn.
In
ICML 2023 Synergy of Scientific and Machine Learning Modeling (SynS&ML) Workshop.
Jul,
2023.
This paper provides a simulated laboratory for making use of Reinforcement Learning (RL) for chemical discovery. Since RL is fairly data intensive, training agents ‘on-the-fly’ by taking actions in the real world is infeasible and possibly dangerous. Moreover, chemical processing and discovery involves challenges which are not commonly found in RL benchmarks and therefore offer a rich space to work in. We introduce a set of highly customizable and open-source RL environments, ChemGymRL, based on the standard Open AI Gym template. ChemGymRL supports a series of interconnected virtual chemical benches where RL agents can operate and train. The paper introduces and details each of these benches using well-known chemical reactions as illustrative examples, and trains a set of standard RL algorithms in each of these benches. Finally, discussion and comparison of the performances of several standard RL methods are provided in addition to a list of directions for future work as a vision for the further development and usage of ChemGymRL.
Generative Causal Representation Learning for Out-of-Distribution Motion Forecasting
In
Proceedings of the 40th International Conference on Machine Learning (ICML).
PMLR,
Honolulu, Hawaii, USA.
Jul,
2023.
Conventional supervised learning methods typically assume i.i.d samples and are found to be sensitive to out-of-distribution (OOD) data. We propose Generative Causal Representation Learning (GCRL) which leverages causality to facilitate knowledge transfer under distribution shifts. While we evaluate the effectiveness of our proposed method in human trajectory prediction models, GCRL can be applied to other domains as well. First, we propose a novel causal model that explains the generative factors in motion forecasting datasets using features that are common across all environments and with features that are specific to each environment. Selection variables are used to determine which parts of the model can be directly transferred to a new environment without fine-tuning. Second, we propose an end-to-end variational learning paradigm to learn the causal mechanisms that generate observations from features. GCRL is supported by strong theoretical results that imply identifiability of the causal model under certain assumptions. Experimental results on synthetic and real-world motion forecasting datasets show the robustness and effectiveness of our proposed method for knowledge transfer under zero-shot and low-shot settings by substantially outperforming the prior motion forecasting models on out-of-distribution prediction.
Balancing Information with Observation Costs in Deep Reinforcement Learning
In
Canadian Conference on Artificial Intelligence.
Canadian Artificial Intelligence Association (CAIAC),
Toronto, Ontario, Canada.
May,
2022.
The use of Reinforcement Learning (RL) in scientific applications, such
as materials design and automated chemistry, is increasing. A major
challenge, however, lies in fact that measuring the state of the system
is often costly and time consuming in scientific applications, whereas
policy learning with RL requires a measurement after each time step. In
this work, we make the measurement costs explicit in the form of a
costed reward and propose the active-measure with costs framework that
enables off-the-shelf deep RL algorithms to learn a policy for both
selecting actions and determining whether or not to measure the state of
the system at each time step. In this way, the agents learn to balance
the need for information with the cost of information. Our results show
that when trained under this regime, the Dueling DQN and PPO agents can
learn optimal action policies whilst making up to 50% fewer state
measurements, and recurrent neural networks can produce a greater than
50% reduction in measurements. We postulate the these reduction can
help to lower the barrier to applying RL to real-world scientific
applications.
Scientific Discovery and the Cost of Measurement – Balancing Information and Cost in Reinforcement Learning
In
1st Annual AAAI Workshop on AI to Accelerate Science and Engineering (AI2ASE).
Feb,
2022.
The use of reinforcement learning (RL) in scientific applications, such as materials design and automated chemistry, is increasing. A major challenge, however, lies in fact that measuring the state of the system is often costly and time consuming in scientific applications, whereas policy learning with RL requires a measurement after each time step. In this work, we make the measurement costs explicit in the form of a costed reward and propose a framework that enables off-the-shelf deep RL algorithms to learn a policy for both selecting actions and determining whether or not to measure the current state of the system at each time step. In this way, the agents learn to balance the need for information with the cost of information. Our results show that when trained under this regime, the Dueling DQN and PPO agents can learn optimal action policies whilst making up to 50% fewer state measurements, and recurrent neural networks can produce a greater than 50% reduction in measurements. We postulate the these reduction can help to lower the barrier to applying RL to real-world scientific applications.
Active Measure Reinforcement Learning for Observation Cost Minimization: A framework for minimizing measurement costs in reinforcement learning
In
Canadian Conference on Artificial Intelligence.
Springer,
2021.
Markov Decision Processes (MDP) with explicit measurement cost are a class of en- vironments in which the agent learns to maximize the costed return. Here, we define the costed return as the discounted sum of rewards minus the sum of the explicit cost of measuring the next state. The RL agent can freely explore the relationship between actions and rewards but is charged each time it measures the next state. Thus, an op- timal agent must learn a policy without making a large number of measurements. We propose the active measure RL framework (Amrl) as a solution to this novel class of problem, and contrast it with standard reinforcement learning under full observability and planning under partially observability. We demonstrate that Amrl-Q agents learn to shift from a reliance on costly measurements to exploiting a learned transition model in order to reduce the number of real-world measurements and achieve a higher costed return. Our results demonstrate the superiority of Amrl-Q over standard RL methods, Q-learning and Dyna-Q, and POMCP for planning under a POMDP in environments with explicit measurement costs.
Reinforcement Learning in a Physics-Inspired Semi-Markov Environment
In
Canadian Conference on Artificial Intelligence.
Springer,
Ottawa, Canada (virtual).
May,
2020.
Compact Representation of a Multi-dimensional Combustion Manifold Using Deep Neural Networks
Sushrut Bhalla,
Matthew Yao,
Jean-Pierre Hickey,
and Mark Crowley
In
European Conference on Machine Learning (ECML-19).
Wurzburg, Germany.
2019.
The computational challenges in turbulent combustion simulations stem from the physical complexities and multi-scale nature of the problem which make it intractable to compute scaleesolving simulations. For most engineering applications, the large scale separation between the flame (typically submillimeter scale) and the characteristic turbulent flow (typically centimeter or meter scale) allows us to evoke simplifying assumptions–such as done for the flamelet model to precompute all the chemical reactions and map them to a low order manifold. The resulting manifold is then tabulated and looked up at runtime. As the physical complexity of combustion simulations increases (including radiation, soot formation, pressure variations etc.) the dimensionality of the resulting manifold grows which impedes an efficient tabulation and look up. In this paper we present a novel approach to model the multidimensional combustion manifold. We approximate the combustion manifold using a neural network function approximator and use it to predict the temperature and composition of the reaction. We present a novel training procedure which is developed to generate a smooth output curve for temperature over the course of a reaction. We then evaluate our work against the current approach of tabulation with linear interpolation in combustion simulations. We also provide an ablation study of our training procedure in the context of overfitting in our model. The combustion dataset used for the modeling of combustion of H2 and O2 in this work is released alongside this paper.